
Escribo este post con motivo de la semana autopublicados, ya que creo que la autoedición, autopublicación y la edición independiente son una fuente de diversidad muy importante y que hay que tener en cuenta, pero que siempre las lleva muy muy putas a la hora de conseguir resultados. Así que os voy a contar una historia de números, jugadores de béisbol y libros.
Corría el año 2002, Brad Pitt nos miraba desde la gran pantalla, mascando chicle, como buen manager del equipo de béisbol con menos presupuesto de toda la liga. Tan pobre era el equipo que dirigía, que tenían que cobrar los refrescos a los jugadores. Y Brad Pitt mascaba chicle mientras escuchaba el partido en la radio, porque Brad Pitt no veía nunca los partidos; pensaba que daba mala suerte.
Es el principio de la película, y Brad Pitt pierde. Por supuesto nuestro héroe no se rinde, ¿habéis visto a Brad Pitt rendirse alguna vez?, y en parte por casualidad contrata a un economista que le dice que el juego está amañado sin saberlo, que los jugadores que todos los demás valoran no son los mejores. Que se puede crear un equipo ganador barato empleando un algoritmo, que se puede vencer a los grandes, por muy pequeño que seas…
Hablo de la película Moneyball, basada en el libro del mismo nombre del autor Michael Lewis (autor de La Gran apuesta, que también tuvo película con Brad Pitt). No hace falta que os cuente el final, lo interesante es que esta película trajo al gran público algo que se sabía desde antes de que existiera Internet ni casi computadores: los algoritmos, aunque sean muy simples, pueden sustituir a los expertos[1]; porque los expertos saben menos de lo que creen y están cargados de prejuicios. El éxito de Moneyball hizo plantearse a muchos emplear algoritmos para tomar decisiones estratégicas: Moneyball para médicos, Moneyball para el ejército y, finalmente, Moneyball para libros.
Para esta semana de Autopublicados he decidido traer un tema poco conocido todavía pero que, a los escritores y editores independientes nos afecta bastante. No se trata del empleo de Big Data para la venta de libros, algo que ya hace Amazon sin compartir sus conclusiones, sino de una cuestión más sútil: saber qué libros van a tener éxito empleando métodos estadísticos sencillos. Esta vez Brad Pitt no es el héroe de la película, sino varias compañías.
¿Y quién es el villano? ¿A quién quieren derrotar estas startups? ¿A las grandes compañías? Desde luego que no. El villano es el vórtice dimensional que siempre ha sido el mercado del libro. De siempre, tanto los editores como los autopublicados lo que hacen es crear libros que luego arrojan a un agujero negro que es el mercado. Si tienen suerte, el vórtice les devolverá dinero, fama y gloria. Si no, devolverá los libros, o nada.
No importa si eres la editorial Planeta o Pepita la escritora, la capacidad de manipular el vórtice es limitada (aunque a Planeta le irá mejor, obviamente) y, por tanto, nunca sabes qué va a pasar con tus libros. La novela del mejor escritor que siempre ha vendido y que se le ha puesto todo el cariño del mundo (y publicidad) puede ser un gran fracaso y, al revés, ese libro al que no le has prestado atención puede convertirse en todo un éxito varios años después.
Hace unos pocos años, las editoriales comenzaron a emplear NielsenBookscan (una filial de la famosa empresa que de siempre medía las audiencias en EE.UU.) para, al menos, saber qué libros habían tenido ventas, algo muy útil para una editorial española que quisiera vender una traducción o para saber el último género de moda. Pero no se llegaba mucho más allá, no había datos suficientes para emplear muchos más métodos.
Ahí nacen Next Big Book y Jellybooks (y puede que más que no haya encontrado), con métodos estadísticos y ambición. Next Big Book es una división de Next Big Sound, que ya realizaba búsqueda de datos para la industria de la música, y contaría con el apoyo de la editorial Mcmillan. Encontraron resultados diversos como que el hecho de tener o no una página en la Wikipedia convencía a los posibles lectores de la compra. Y ahí acaba su parte en este relato. No he podido encontrar más datos sobre ellos, es como si en 2014 desaparecieran.
En cuanto a Jellybooks, se trata de una startup londinense. Comenzaron ofreciendo clásicos gratuitos y viendo cómo los leía la gente y ahora ofrecen sus servicios a todo tipo de editoriales. ¿Sus métodos? Dan libros electrónicos gratuitos a mucha gente (hablamos de unas 800 personas) y les dejan a su aire. Cada vez que llegan a cierta parte del libro tienen que apretar un botón y, después, les realizan una serie de test a los que han conseguido finalizar el libro sobre la cubierta, si lo recomendarían, etc. El hecho de que sean al menos 800 lectores, hace que los resultados sean estadísticamente relevantes[2]. Y estos son algunos de los resultados que han hecho públicos:
- Pocos libros son leídos por la totalidad de los lectores o siquiera una mayoría. Apenas el 5 % de los libros testeados fueron leídos por más del 75 % de los lectores. Y el número de libros leídos por más del 50 % de los lectores no llega a la mitad.
- Las mujeres abandonan un libro tras 50 – 100 páginas, mientras que los hombres lo hacen tras apenas 30 – 50.
- Es decir, un libro de éxito tiene esta pinta (fuente: The New York Times).
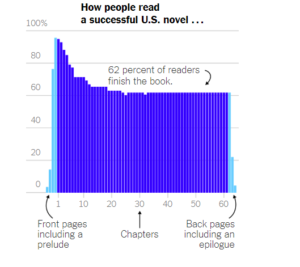
- Y un montón de datos, dependientes de cada libro, sobre si la cubierta es apropiada o no para el libro empleando métodos de doble ciego (como se hace en las pruebas médicas).
Con estos datos las grandes editoriales pueden maximizar el beneficio y putear al temido vórtice. Pero claro, toda lucha tiene daños colaterales. Y aquí viene la parte peliaguda, estos datos indican a la editorial si un libro contratado tiene más o menos probabilidades de éxito o si su cubierta no está bien concebida. Si la editorial considera que no hay manera de convertir un libro en un éxito, simplemente no lo publicitarán.
Esto, en sí, es una mala noticia para los autores. Porque implica que, a pesar de tener un contrato con una editorial potente, su libro va a ser menos publicitado que el resto si no ha pasado las pruebas; con la que las probabilidades de que su obra vaya bien son mínimas. Tal es así que el New York Times indica en un artículo sobre Jellybooks que las editoriales que emplean sus servicios no han querido decir sus nombres.
Pero también es una mala noticia para aquellas editoriales sin capacidad para emplear sus servicios (como no pueden emplear los de Nielsen, o cualquier otro que sea demasiado caro), porque implica que se van a enfrentar al mercado sin la ayuda de estas herramientas, por lo que la fuente de diversidad que mencioné al principio lo va a tener más difícil todavía si cabe. Para los que creen que esto son cosas que se hacen en el mundo exterior, según una serie de charlas que la compañía ha dado en Italia, el año que viene empezaran a operar en español.
¿Qué podemos hacer al respecto? En realidad lo mismo de siempre: ser consumidores responsables. Si, como yo, consideráis que la mejor forma de apoyar la cultura es apoyando la publicación independiente, el movimiento se muestra andando. Hay material de gran calidad sin que hoy en día haga falta romperse la cabeza para conseguir buenas obras de grandes escritores que todavía no han tenido una oportunidad en las editoriales grandes (y que puede que nunca la tengan). Basta con comprarlas.
[1] https://en.wikipedia.org/wiki/Paul_E._Meehl#Clinical_versus_statistical_prediction
[2] Porque según la ley de los pequeños números, cuanto menor sea la muestra, más probabilidad hay de resultados extraños que no tienen que ver con la realidad.